
Hyperledger fabric 1.0 代码解析 之 Orderer Service
转自知乎: https://zhuanlan.zhihu.com/p/25358777 对内容进行了微调和排版
1 总体架构
1.1 Orderer简介
Orderer作为Fabric共识服务的网络节点。原文介绍:
A centralized or decentralized service that orders transactions in a block. You can select different implementations of the “ordering” function - e.g “solo” for simplicity and testing, Kafka for crash fault tolerance, or sBFT/PBFT for byzantine fault tolerance. You can also develop your own protocol to plug into the service.
The hyperledger fabric ordering service is intended to provide an atomic broadcast ordering service for consumption by the peers. This means that many clients may submit messages for ordering, and all clients are delivered the same series of ordered batches in response.
1.2主要模块
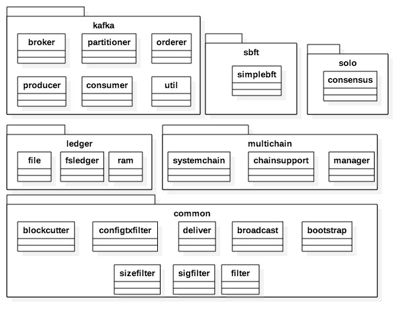 模块说明:
模块说明:
一、Kafka
1、Broker:Kafka的Broker信息
2、Partitioner:kafka的基础连接信息,包括topic、partition
3、Consumer、Producer:分别为kafka的消费、生产者接口
4、Orderer:消息的排序与数据块管理接口
二、Multichain
封装了Chain操作相关接口。Chain目前有四种实现方式:SystemChain以及其它Chain(Kafaka、Solo、Sbft)。其中SystemChain为必须,其他三个根据配置启用。
1、manager:主要负责chain的创建与访问控制。
2、chainsupport:主要负责chain的操作接口,包括新增签名,数据块写入等。
3、systemchain: 封装了systemchain的相关操作,systemchain主要用于管理配置以及安全相关控制。
三、ledger
orderer对外服务过程中,允许客户端(例如peer)批量获取消息, 所以orderer需要维护历史消息拷贝,消息数量可以是有限的也可以是无限的,通过配置进行修改。这些历史消息维护在Orderer的Ledger模块中。目前Orderer存储支持多种方式:(Orderer的ledger非Fabric整个系统的Ledger模块,此Ledger特指Orderer自身的数据存储引擎)
1、File: 2、json:实现了以json格式为存储方式的的文件系统账本。该账本实现方式支持容灾,但性能不高, 3、Ram : Ram实现了一个简单的基于内存存储的账本,可以自由调整数据存储相关参数,例如历史存储大小等。该账本不支持容灾,每次系统挂掉,内存数据将会消失,重启后,将会重新建立新的账本。
四、common
提供了一些公共的接口,包括配置信息、消息的分组与组装、消息过滤规则等。
2、代码剖析
2.1 通信接口
Orderer主要提供两个Grpc接口:Broadcast和Deliver,两个接口面向客户端(fabric一般指peer)通信。客户端通过Broadcast向orderer发送消息,orderer通过Broadcast获取客户端的消息并将其储存。客户端通过Deliver接口从Order获取数据。
service AtomicBroadcast {
// Broadcast接收客户端消息并将消息存入orderer
rpc Broadcast(stream common.Envelope) returns (stream BroadcastResponse) {}
//客户端从orderer获取数据的接口
rpc Deliver(stream common.Envelope) returns (stream DeliverResponse) {}
}
2.2核心消息结构
2.2.1 Block
Block: Orderer中消息数据的组织形式,以块(Block)的形式存在内存或者文件中(可配置),每个块可能会存在多条消息(根据配置:每个块的大小以及记录数决定)。
//数据块头部结构
message BlockHeader {
uint64 number = 1; // blockchain的当前所处位置,从0开始标号
bytes previous_hash = 2; //前一个block chain header的hash 值
bytes data_hash = 3; // BlockData的hash 值, 通过MerkleTree计算
}
//数据块数据结构
message BlockData {
repeated bytes data = 1;
}
//数据块元数据信息,包括自身相关的基础信息
message BlockMetadata {
repeated bytes metadata = 1;
}
//数据块结构
message Block {
BlockHeader header = 1;
BlockData data = 2;
BlockMetadata metadata = 3;
}
2.2.2 SeekInfo
SeekInfo作为客户端使用Deliver接口时所传送的参数信息,主要是为了获取block数据的方式。
message SeekInfo {
enum SeekBehavior {
BLOCK_UNTIL_READY = 0; //遇到缺失的Block时,等待缺失的Block生成
FAIL_IF_NOT_READY = 1; //遇到缺失的Block时,直接返回错误
}
SeekPosition start = 1; //消息开始获取的位置
SeekPosition stop = 2; //消息停止获取的位置
SeekBehavior behavior = 3; //遇到缺失block的表现(behavior)
}
message SeekPosition { //查找Block位置类型
oneof Type {
SeekNewest newest = 1; //从最新位置开始查找
SeekOldest oldest = 2; //从最开始位置开始查找
SeekSpecified specified = 3; //自定义位置
}
}
2.2.3 KafkaMessage
KafkaMessage:Orderer与Kafka的通信消息结构。
message KafkaMessage { //KAFKA消息主结构
oneof Type {
KafkaMessageRegular regular = 1; //orderer的正常消息:当前已生成Block的编号
KafkaMessageTimeToCut time_to_cut = 2; //orderer的生产块事件消息
KafkaMessageConnect connect = 3; //KAFKA与Orderer的连接消息
}
}
message KafkaMessageRegular {
bytes payload = 1;
}
message KafkaMessageTimeToCut {
uint64 block_number = 1;
}
message KafkaMessageConnect {
bytes payload = 1;
}
2.3 Orderer服务
Orderer服务主要分为三种:Solo、Kafka、Sbft。本文只介绍Solo、Kafka。
Solo Orderer: The solo orderer is intended to be an extremely easy to deploy, non-production orderer. It consists of a single process which serves all clients, so no `consensus’ is required as there is a single central authority. There is correspondingly no high availability or scalability. This makes solo ideal for development and testing, but not deployment. The Solo orderer depends on a backing orderer ledger. Kafka Orderer : The Kafka orderer leverages the Kafka pubsub system to perform the ordering, but wraps this in the familiar ab.proto definition so that the peer orderer client code does not to be written specifically for Kafka. In real world deployments, it would be expected that the Kafka proto service would bound locally in process, as Kafka has its own robust wire protocol. However, for testing or novel deployment scenarios, the Kafka orderer may be deployed as a network service. Kafka is anticipated to be the preferred choice production deployments which demand high throughput and high availability but do not require byzantine fault tolerance. The Kafka orderer does not utilize a backing orderer ledger because this is handled by the Kafka brokers.
2.3.1 Orderer-Solo
order-solo模式作为单节点通信模式,所有从peer收到的消息都在本节点进行排序与生成数据块,详细流程见下图:
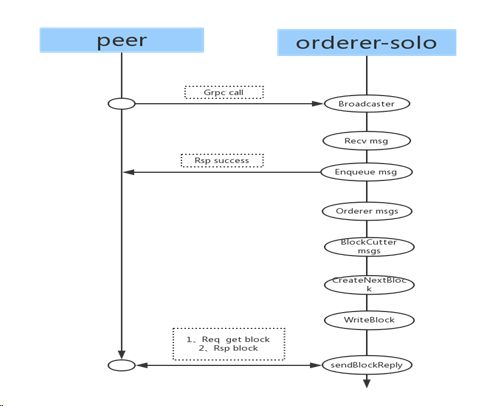 order-solo过程分析:
Peer(客户端)通过GRPC发起通信,与Orderer连接成功之后,便可以向Orderer发送消息。Orderer通过Recv接口接收Peer发送过来的消息,Orderer将接收到的消息生成数据块,并将数据块存入ledger,peer通过deliver接口从orderer中的ledger获取数据块。
order-solo过程分析:
Peer(客户端)通过GRPC发起通信,与Orderer连接成功之后,便可以向Orderer发送消息。Orderer通过Recv接口接收Peer发送过来的消息,Orderer将接收到的消息生成数据块,并将数据块存入ledger,peer通过deliver接口从orderer中的ledger获取数据块。
2.3.2 Orderer-Kafka
2.3.2.1 BroadCast
Broadcast主要接收Peer的数据并在Orderer里面生成一系列数据块,主要流程见下图:
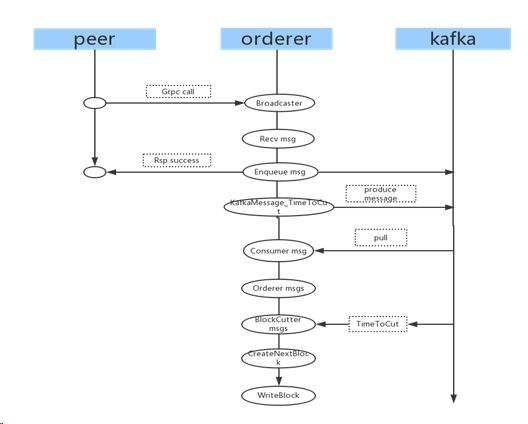
Broadcast过程分析:Peer(客户端)通过GRPC发起通信,与Orderer连接成功之后,便可以向Orderer发送消息。Orderer通过Recv接口接收Peer发送过来的消息,并将消息推送到Kafka。同时与Kafka相连接的Orderer通过Consumer实例消费Kafka上的消息,将消费的消息进行同一排序(Order),排序完成后,当达到生成数据块(Block)的条件(条件有两个1:下一数据块定时器到期,定时器通过向Orderer向Kafka发送定时器消息,再通过Kafka消费来达到定时效果。2:每消费一条真实数据,就触发判断是否达到生成一个新的数据块条件,该条件由当前待生成数据块的数据总的大小以及记录数决定),并创建新的数据块(CreateNextBlock),创建成功则将数据块写入ledger(WriteBlock)。
2.3.2.2 Deliver
Deliver过程分析:
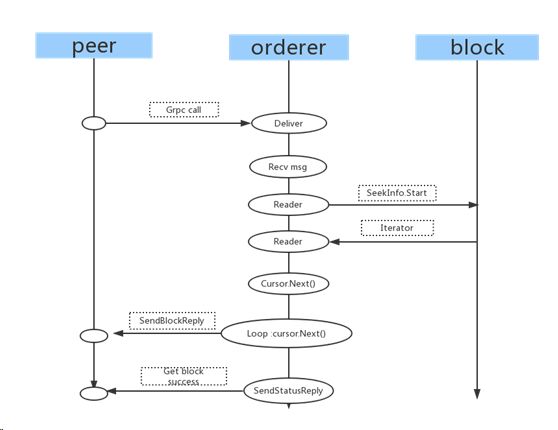 Peer通过GRPC与orderer建立通信,连接成功以后,通过deliver接口发起获取数据请求。Orderer通过recv接口接收到数据获取请求,分析请求参数(SeekInfo_Start:1、SeekPosition_Oldest:从第一条数据块开始获取。2、SeekPosition_Newest:从最新一个数据块开始获取 3、SeekPosition_Specified:从指定数据块数获取)。Orderer从ledger中获取数据块迭代器入口,循环迭代器获取所有的数据块,每获取一个数据块同时就获取到的数据块返回给peer,知道所有数据块获取完,最后向peer返回获取成功状态。
Peer通过GRPC与orderer建立通信,连接成功以后,通过deliver接口发起获取数据请求。Orderer通过recv接口接收到数据获取请求,分析请求参数(SeekInfo_Start:1、SeekPosition_Oldest:从第一条数据块开始获取。2、SeekPosition_Newest:从最新一个数据块开始获取 3、SeekPosition_Specified:从指定数据块数获取)。Orderer从ledger中获取数据块迭代器入口,循环迭代器获取所有的数据块,每获取一个数据块同时就获取到的数据块返回给peer,知道所有数据块获取完,最后向peer返回获取成功状态。
2.4 GenesisBlock
genesisBlock随着Orderer的启动而自动创建的初始块,主要在Orderer运行过程中提供基础配置,包括网络、通道(channel)等信息。
genesisBlock分为两种模式:
1、provisional:通过配置动态加载配置方式,创建genesis块
2、file: 通过加载文件形式创建genesis块(例如从固定文件 GenesisFile: ./genesisblock创建)
Provisiona区块创建过程:
// New returns a new provisional bootstrap helper.
func New(conf *genesisconfig.Profile) Generator {
bs := &bootstrapper{
channelGroups: []*cb.ConfigGroup{
/*一些默认的配置信息,默认的hash算法,默认的policy*/
......
},
}
if conf.Orderer != nil {
// Orderer地址
oa := config.TemplateOrdererAddresses(conf.Orderer.Addresses)
oa.Values[config.OrdererAddressesKey].ModPolicy = OrdererAdminsPolicy
bs.ordererGroups = []*cb.ConfigGroup{
oa,
// Orderer Config Types
config.TemplateConsensusType(conf.Orderer.OrdererType),
config.TemplateBatchSize(&ab.BatchSize{
/*conf文件中获得BatchSize信息,包最大消息数MaxMessageCount,包大小的上限AbsoluteMaxBytes,包大小的优先上限设置PreferredMaxBytes*/
......
}),
config.TemplateBatchTimeout(conf.Orderer.BatchTimeout.String()),
config.TemplateChannelRestrictions(conf.Orderer.MaxChannels),
// Initialize the default Reader/Writer/Admins orderer policies, as well as block validation policy
......
}
for _, org := range conf.Orderer.Organizations {
/*对于每一个org验证msp,并将其按照追加到bs的ordererGroups*/
......
}
switch conf.Orderer.OrdererType {
case ConsensusTypeSolo:
case ConsensusTypeKafka:
//kafka broker配置
bs.ordererGroups = append(bs.ordererGroups, config.TemplateKafkaBrokers(conf.Orderer.Kafka.Brokers))
default:
// panic(fmt.Errorf("Wrong consenter type value given: %s", conf.Orderer.OrdererType))
}
}
if conf.Application != nil {
/*默认项的配置,主要是Organizations中各个org的验证和设置*/
......
}
if conf.Consortiums != nil {
/*默认项的配置*/
......
}
return bs
}
// GenesisBlock TODO Deprecate and remove
func (bs *bootstrapper) GenesisBlock() *cb.Block {
block, err := genesis.NewFactoryImpl(
configtx.NewModPolicySettingTemplate(
configvaluesmsp.AdminsPolicyKey,
configtx.NewCompositeTemplate(
configtx.NewSimpleTemplate(bs.consortiumsGroups...),
bs.ChannelTemplate(),
),
),
).Block(TestChainID)
if err != nil {
panic(err)
}
return block
}
2.5 Ledger
2.5.1 Ram
数据块存储结构:
type simpleList struct {
next *simpleList
signal chan struct{}
block *cb.Block
}
type ramLedger struct {
maxSize int //ledger可存储Block数量的最大值
size int //当前ledger已存储的Block数量
oldest *simpleList //指向ledger上次已获取Block位置的指针??
newest *simpleList //指向ledger最新Block位置的指针
}
主要接口
GetOrCreate(chainID string):获取一个存在的或者创建一个名叫chainID的区块
ChainIDs:获取当前ledger中的所有区块
newChain:新建一个区块
Height:获取当前区块个数
Iterator(startPosition *ab.SeekPosition):返回首地址为startPosition区块访问迭代器
Append(block *cb.Block):往ledger新加一个块
// Append 新加一个块到ledger,ram实现
func (rl *ramLedger) Append(block *cb.Block) error {
//检查新增Block的编号是否在ledger上连续
if block.Header.Number != rl.newest.block.Header.Number+1 {
return fmt.Errorf("Block number should have been %d but was %d",
rl.newest.block.Header.Number+1, block.Header.Number)
}
//跳过 genesis block(genesis block的number为0)
if rl.newest.block.Header.Number+1 != 0 {
//检查数据HASH是否相等
if !bytes.Equal(block.Header.PreviousHash, rl.newest.block.Header.Hash()) {
return fmt.Errorf("Block should have had previous hash of %x but was %x",
rl.newest.block.Header.Hash(), block.Header.PreviousHash)
}
}
//将新增的Block块加入到Ledger
rl.appendBlock(block)
}
func (rl *ramLedger) appendBlock(block *cb.Block) {
rl.newest.next = &simpleList{//新建一个新的空数据块
signal: make(chan struct{}),
block: block,
}
lastSignal := rl.newest.signal
logger.Debugf("Sending signal that block %d has a successor", rl.newest.block.Header.Number)
rl.newest = rl.newest.next
close(lastSignal)
rl.size++ //当前Ledger数据块数量增1
if rl.size > rl.maxSize {
logger.Debugf("RAM ledger max size about to be exceeded, removing oldest item: %d",
rl.oldest.block.Header.Number)
rl.oldest = rl.oldest.next
rl.size--
}
}
2.6 Block
数据块生成是ORDER的核心功能,它从客户端接收过来的消息进行统一的排序, 并按照一定的组织方式进行存储,orderer将接收到的消息按消息记录数或者消息的大小组成一个固定的数据块,这些数据块存储在RAM或者FILE中, 提高了fabric系统对消息转发以及使用效率。
2.6.1 Block创建
数据块生成主要分成两个接口:
1、ordered:负责消息的排序。
2、cut:负责消息的切块。
func (r *receiver) Ordered(msg *cb.Envelope) ([][]*cb.Envelope, [][]filter.Committer, bool) {
committer, err := r.filters.Apply(msg) // 判断消息是否可接受
if err != nil {
logger.Debugf("Rejecting message: %s", err)
return nil, nil, false
}
// 若要求独立切分,或者消息大小超过PreferredMaxBytes,意思是目前这个不用放等待队列,可以直接切
if committer.Isolated() || messageSizeBytes > r.sharedConfigManager.BatchSize().PreferredMaxBytes {
if len(r.pendingBatch) > 0 { //当前存在等待切分的消息,则先把之前等待的切块
messageBatch, committerBatch := r.Cut() //对之前等待切分的消息进行切分,返回块
messageBatches = append(messageBatches, messageBatch) //返回的块加入到队列
committerBatches = append(committerBatches, committerBatch) //返回的commiter加入到队列
}
// 将新的消息独立作为一个新的块
messageBatches = append(messageBatches, []*cb.Envelope{msg})
committerBatches = append(committerBatches, []filter.Committer{committer})
return messageBatches, committerBatches, true
}
//计算将当前消息的加入到之前待切分的队列,所组成的块大小是否会超出PreferredMaxBytes
messageWillOverflowBatchSizeBytes := r.pendingBatchSizeBytes+messageSizeBytes > r.sharedConfigManager.BatchSize().PreferredMaxBytes
//达到了切分块的条件,将新的消息与等待切块的消息一起组成一个块
if messageWillOverflowBatchSizeBytes { //将之前等待的进行切块
messageBatch, committerBatch := r.Cut()
messageBatches = append(messageBatches, messageBatch)
committerBatches = append(committerBatches, committerBatch)
}
//将消息加入待切块区
r.pendingBatch = append(r.pendingBatch, msg)
r.pendingBatchSizeBytes += messageSizeBytes
r.pendingCommitters = append(r.pendingCommitters, committer)
//如果待处理的消息个数到达限制,切块处理
if uint32(len(r.pendingBatch)) >= r.sharedConfigManager.BatchSize().MaxMessageCount {
messageBatch, committerBatch := r.Cut()
messageBatches = append(messageBatches, messageBatch)
committerBatches = append(committerBatches, committerBatch)
}
// return nils instead of empty slices
if len(messageBatches) == 0 {
return nil, nil, true
}
return messageBatches, committerBatches, true
}
//该接口主要放回待切块的数据,并将原结构数据清空,以接收下一个块的数据
func (r *receiver) Cut() ([]*cb.Envelope, []filter.Committer) {
batch := r.pendingBatch
r.pendingBatch = nil
committers := r.pendingCommitters
r.pendingCommitters = nil
r.pendingBatchSizeBytes = 0
return batch, committers
}
2.7 Kafka
Kafka消息收发处理主流程:通过主循环loop接口,接收两类消息事件来进行对消息排序并写入区块:
1、下一数据块生成定时器事件:系统会设置一个定时的数据块生成定时器,每到定时器到期,都会检查是否有新的数据块需要生成, 如果需要就生成新的数据块。
2、 新消息事件:每到一条新的消息,系统都会重新判断是否需要有新的数据块需要生成,如果有,就将消息进行排序并生成一块新的数据块。
func (ch *chainImpl) loop() {
//...
for {
select {
case in := <-ch.consumer.Recv(): // 消费者收到一条消息
if err := proto.Unmarshal(in.Value, msg); err != nil {…..} //解析PROTOBUF
switch msg.Type.(type) {
case *ab.KafkaMessage_Connect: //KAFKA连接信息,跳过
continue
case *ab.KafkaMessage_TimeToCut: //区块切分定时任务到期
ttcNumber = msg.GetTimeToCut().BlockNumber
if ttcNumber == ch.lastCutBlock+1 {
//获取可生成下一个区块的数据
batch, committers := ch.support.BlockCutter().Cut()
if len(batch) == 0 { //没有数据
return
}
block := ch.support.CreateNextBlock(batch) //创建一个新的数据块
//...
//将新的区块数据写入到相应的结构信息中(RAM 或者FILE)
ch.support.WriteBlock(block, committers, encodedLastOffsetPersisted)
ch.lastCutBlock++
continue
} else if ttcNumber > ch.lastCutBlock+1 {
return
}
case *ab.KafkaMessage_Regular: //收到一条新的消息
env := new(cb.Envelope)
if err := proto.Unmarshal(msg.GetRegular().Payload, env); err != nil { //解析数据
continue
}
//获取可生成下一个区块的数据
batches, committers, ok := ch.support.BlockCutter().Ordered(env)
if ok && len(batches) == 0 && timer == nil {
//重新设置下一个区块生成定时器
timer = time.After(ch.batchTimeout)
continue
}
for i, batch := range batches {
block := ch.support.CreateNextBlock(batch) //创建一个新的数据块
//将新的区块数据写入到相应的结构信息中(RAM 或者FILE)
ch.support.WriteBlock(block, committers[i], encodedLastOffsetPersisted)
ch.lastCutBlock++
}
if len(batches) > 0 {
timer = nil
}
}
case <-timer: //下一个区块生成定时器到期,发送切块信号,与ab.KafkaMessage_TimeToCut对应
logger.Debugf("Time-to-cut block %d timer expired", ch.lastCutBlock+1)
timer = nil
if err :=
ch.producer.Send(ch.partition, utils.MarshalOrPanic(newTimeToCutMessage(ch.lastCutBlock+1))); err != nil {
}
case <-ch.exitChan: // When Halt() is called
return
}
}
2.8 Solo
Solo 消息收发处理主流程:
通过主循main接口,接收两类消息事件来进行对消息排序并写入区块:
1、下一数据块生成定时器事件:系统会设置一个定时的数据块生成定时器,每到定时器到期,都会检查是否有新的数据块需要生成,如果需要就生成新的数据块。
2、 新消息事件:每到一条新的消息,系统都会重新判断是否需要有新的数据块需要生成,如果有,就将消息进行排序并生成一块新的数据块。
func (ch *chain) main() {
//设置下一个区块生成定时器
var timer <-chan time.Time
for {
select {
case msg := <-ch.sendChan:
//获取可生成下一个区块的数据
batches, committers, ok := ch.support.BlockCutter().Ordered(msg)
if ok && len(batches) == 0 && timer == nil {
timer = time.After(ch.batchTimeout)
continue
}
for i, batch := range batches {
block := ch.support.CreateNextBlock(batch)
/*将新的区块数据写入到相应的结构信息中(RAM 或者FILE),
WriteBlock中committer执行commit,里面可能有大量操作*/
ch.support.WriteBlock(block, committers[i], nil)
}
if len(batches) > 0 {
timer = nil
}
case <-timer:
timer = nil
//获取可生成下一个区块的数据
batch, committers := ch.support.BlockCutter().Cut()
if len(batch) == 0 {
continue
}
block := ch.support.CreateNextBlock(batch)
ch.support.WriteBlock(block, committers, nil)
case <-ch.exitChan:
return
}
}
}