
Raft在etcd中的实现(五)snapshot相关
snapshot概念回顾
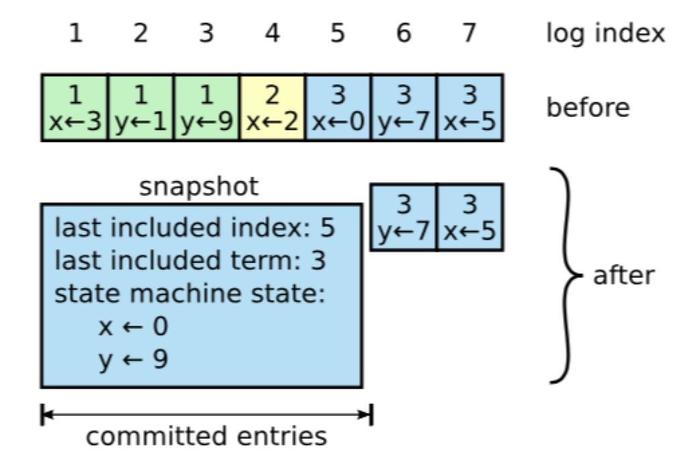
在正常运行过程中,raft集群的日志增长非常的快。通常使用镜像快照来压缩日志。即通过将当前的state写入到存储的snapshot中,然后到该点的日志即可被丢弃。
问题
该篇问题主要从业务的角度入手,介绍snapshot的一些相关问题。问题中涉及到raft共识部分的仅有InstallSnapshot RPC的部分。
- 何时触发snapshot操作
- 将哪些数据保存到snapshot
- 如何将数据保存到snapshot
- 何时会触发InstallSnapshot RPC
- 何时会用到snapshot中的数据
代码详解
以etcd中的raftexample为例。来讲解下example中是如何处理上述问题的。
何时触发snapshot操作
- node.Ready()有新的数据时,会触发一系列操作,其中包括写wal,将可以commit的条目交由state machine执行等,snapshot的触发也在这里,具体实现是调用的maybeTriggerSnapshot。
func (rc *raftNode) serveChannels() {
//...
// event loop on raft state machine updates
for {
select {
//...
// store raft entries to wal, then publish over commit channel
case rd := <-rc.node.Ready():
rc.wal.Save(rd.HardState, rd.Entries)
if !raft.IsEmptySnap(rd.Snapshot) {
rc.saveSnap(rd.Snapshot)
rc.raftStorage.ApplySnapshot(rd.Snapshot)
rc.publishSnapshot(rd.Snapshot)
}
rc.raftStorage.Append(rd.Entries)
rc.transport.Send(rd.Messages)
if ok := rc.publishEntries(rc.entriesToApply(rd.CommittedEntries)); !ok {
rc.stop()
return
}
//尝试触发snapshot
rc.maybeTriggerSnapshot()
rc.node.Advance()
}
}
}
- maybeTriggerSnapshot首先判断appliedIndex和snapshotIndex的大小差距,是否达到设定的snapCount。从这里可以看出example中是按照条目的数目来确认是否触发snapshot的。其他的触发条件只需要在此处作相应判断即可。
func (rc *raftNode) maybeTriggerSnapshot() {
//判断日志条目数目,确定是否需要进行snapshot
if rc.appliedIndex-rc.snapshotIndex <= rc.snapCount {
return
}
log.Printf("start snapshot [applied index: %d | last snapshot index: %d]", rc.appliedIndex, rc.snapshotIndex)
//获取snapshot的数据,这里是调用初始化时传进来的函数getSnapshot,
data, err := rc.getSnapshot()
if err != nil {
log.Panic(err)
}
//创建snapshot,可以看出这里会记录appliedIndex,当前的confState,以及刚才的snapshot数据
snap, err := rc.raftStorage.CreateSnapshot(rc.appliedIndex, &rc.confState, data)
if err != nil {
panic(err)
}
//将snapshot存储到文件中
if err := rc.saveSnap(snap); err != nil {
panic(err)
}
compactIndex := uint64(1)
if rc.appliedIndex > snapshotCatchUpEntriesN {
compactIndex = rc.appliedIndex - snapshotCatchUpEntriesN
}
if err := rc.raftStorage.Compact(compactIndex); err != nil {
panic(err)
}
log.Printf("compacted log at index %d", compactIndex)
rc.snapshotIndex = rc.appliedIndex
}
将哪些数据保存到snapshot
- 保存什么数据取决于业务的需求,一般来讲,应该如文章开始的图片那样,保存state machine的状态。example可以看到是把一个kv数据库(实质是一个map[string]string )直接进行了json Marshal操作。
- 除了state machine的数据外,snapshot中还会保存一些当前日志状态的,如文章开始的图片中的last included index, last included term。
- etcd的实现中也可以将当前集群的节点配置状态也进行保存。
func (s *kvstore) getSnapshot() ([]byte, error) {
s.mu.Lock()
defer s.mu.Unlock()
return json.Marshal(s.kvStore)
}
// func maybeTriggerSnapshot
//获取snapshot的数据,这里是调用初始化时传进来的函数getSnapshot,
data, err := rc.getSnapshot()
if err != nil {
log.Panic(err)
}
//创建snapshot,可以看出这里会记录appliedIndex,当前的confState,以及刚才的snapshot数据
snap, err := rc.raftStorage.CreateSnapshot(rc.appliedIndex, &rc.confState, data)
if err != nil {
panic(err)
}
// CreateSnapshot makes a snapshot which can be retrieved with Snapshot() and
// can be used to reconstruct the state at that point.
// If any configuration changes have been made since the last compaction,
// the result of the last ApplyConfChange must be passed in.
func (ms *MemoryStorage) CreateSnapshot(i uint64, cs *pb.ConfState, data []byte) (pb.Snapshot, error) {
ms.Lock()
defer ms.Unlock()
//判断i的值是否有效,太小说明已经打在之前的snapshot中了,太大说明当前还没有那么多日志条目
if i <= ms.snapshot.Metadata.Index {
return pb.Snapshot{}, ErrSnapOutOfDate
}
offset := ms.ents[0].Index
if i > ms.lastIndex() {
raftLogger.Panicf("snapshot %d is out of bound lastindex(%d)", i, ms.lastIndex())
}
//last last included index, last included term
ms.snapshot.Metadata.Index = i
ms.snapshot.Metadata.Term = ms.ents[i-offset].Term
//cs是当前集群节点状态,是一个id组成的数组
if cs != nil {
ms.snapshot.Metadata.ConfState = *cs
}
//state machine的数据
ms.snapshot.Data = data
return ms.snapshot, nil
}
如何将数据保存到snapshot
- raftexample中调用saveSnap。这里的saveSnapshot调用了wal以及snapshotter中的实现。业务中也可以自己实现该部分。具体wal和snapshotter中的实现,之后在相关模块中再分析。
//将snapshot存储到文件中
if err := rc.saveSnap(snap); err != nil {
panic(err)
}
func (rc *raftNode) saveSnap(snap raftpb.Snapshot) error {
// must save the snapshot index to the WAL before saving the
// snapshot to maintain the invariant that we only Open the
// wal at previously-saved snapshot indexes.
walSnap := walpb.Snapshot{
Index: snap.Metadata.Index,
Term: snap.Metadata.Term,
}
if err := rc.wal.SaveSnapshot(walSnap); err != nil {
return err
}
if err := rc.snapshotter.SaveSnap(snap); err != nil {
return err
}
return rc.wal.ReleaseLockTo(snap.Metadata.Index)
}
何时会触发InstallSnapshot RPC
- 当有新节点加入或者有节点落后的比较多的时候,有可能会触发leader向其发送InstallSnapshot RPC。触发的情况基本上就是节点需要的数据leader这边已经打到snapshot中了,所以只能把snapshot发过去。具体逻辑在sendAppend中。
// sendAppend sends RPC, with entries to the given peer.
func (r *raft) sendAppend(to uint64) {
pr := r.getProgress(to)
if pr.IsPaused() {
return
}
m := pb.Message{}
m.To = to
//寻找节点的Next对应的上一个index和term
term, errt := r.raftLog.term(pr.Next - 1)
ents, erre := r.raftLog.entries(pr.Next, r.maxMsgSize)
//出错说明应该是打到snapshot中了
if errt != nil || erre != nil { // send snapshot if we failed to get term or entries
if !pr.RecentActive {
r.logger.Debugf("ignore sending snapshot to %x since it is not recently active", to)
return
}
m.Type = pb.MsgSnap
//拿到当前的snapshot信息
snapshot, err := r.raftLog.snapshot()
if err != nil {
if err == ErrSnapshotTemporarilyUnavailable {
r.logger.Debugf("%x failed to send snapshot to %x because snapshot is temporarily unavailable", r.id, to)
return
}
panic(err) // TODO(bdarnell)
}
if IsEmptySnap(snapshot) {
panic("need non-empty snapshot")
}
m.Snapshot = snapshot
sindex, sterm := snapshot.Metadata.Index, snapshot.Metadata.Term
r.logger.Debugf("%x [firstindex: %d, commit: %d] sent snapshot[index: %d, term: %d] to %x [%s]",
r.id, r.raftLog.firstIndex(), r.raftLog.committed, sindex, sterm, to, pr)
pr.becomeSnapshot(sindex)
r.logger.Debugf("%x paused sending replication messages to %x [%s]", r.id, to, pr)
} else {
//...
}
//发送snapshot信息给节点
r.send(m)
}
何时会用到snapshot中的数据
snapshot数据主要有两大用途
- 节点挂掉之后重启,可以从snapshot中快速恢复
- 新节点加入或者有节点落后leader特别多,可以通过snapshot快速同步
重启时使用snapshot中的数据
节点重新启动的时候会调用replayWAL对snapshot以及wal中的日志条目进行回放。回放主要是将snapshot内容放入snapshot,将wal放入自身的日志条目中。
func (rc *raftNode) startRaft() {
//...
oldwal := wal.Exist(rc.waldir)
rc.wal = rc.replayWAL()
//...
}
回放: a. 将snapshot文件中的内容读出来。 b. 并根据该内容中last include Index和last include Term将wal文件中对应的之后的日志条目内容读出来。 c. ApplySnapshot,将读到的snapshot放到raftStorage的snapshot中。SetHardState,将hardState内容放到raftStorage的hardState中。Append(ents),将wal读出的日志条目,放到raftStorage的ents中。 d. 标lastIndex,发送nil给commitC(nil的作用是告知接收到的地方,需要处理snapshot)
// replayWAL replays WAL entries into the raft instance.
func (rc *raftNode) replayWAL() *wal.WAL {
log.Printf("replaying WAL of member %d", rc.id)
//loadSnapshot文件中的内容,这里实际上是调用的snapshotter那边的Load函数
snapshot := rc.loadSnapshot()
//从wal文件中读取日志条目信息
w := rc.openWAL(snapshot)
_, st, ents, err := w.ReadAll()
if err != nil {
log.Fatalf("raftexample: failed to read WAL (%v)", err)
}
rc.raftStorage = raft.NewMemoryStorage()
if snapshot != nil {
//ApplySnapshot,将读到的snapshot放到raftStorage的snapshot中
rc.raftStorage.ApplySnapshot(*snapshot)
}
rc.raftStorage.SetHardState(st)
// append to storage so raft starts at the right place in log
rc.raftStorage.Append(ents)
// send nil once lastIndex is published so client knows commit channel is current
if len(ents) > 0 {
rc.lastIndex = ents[len(ents)-1].Index
}
rc.commitC <- nil
return w
}
处理回放:
func (s *kvstore) readCommits(commitC <-chan *string, errorC <-chan error) {
for data := range commitC {
if data == nil {
//处理回放的snapshot
snapshot, err := s.snapshotter.Load()
if err == raftsnap.ErrNoSnapshot {
return
}
if err != nil && err != raftsnap.ErrNoSnapshot {
log.Panic(err)
}
log.Printf("loading snapshot at term %d and index %d", snapshot.Metadata.Term, snapshot.Metadata.Index)
//从snapshot中拿到数据
if err := s.recoverFromSnapshot(snapshot.Data); err != nil {
log.Panic(err)
}
continue
}
//...
}
//...
}
func (s *kvstore) recoverFromSnapshot(snapshot []byte) error {
var store map[string]string
//raftexample中只是简单的将map[string]string复制给了当前的kvStore
if err := json.Unmarshal(snapshot, &store); err != nil {
return err
}
s.mu.Lock()
s.kvStore = store
s.mu.Unlock()
return nil
}
处理InstallSnapshot
- 接收到installSnapshot的节点会调用handleSnapshot来处理消息。
- 如果snapshot消息比较旧,说明本地已有包含该snapshot的日志条目。则返回自身的commited值给leader,告诉leader自己已有这些数据了。
- 如果snapshot消息比较新,重储log和raft节点的成员配置信息。返回新的lastIndex值给leader。
func (r *raft) handleSnapshot(m pb.Message) {
sindex, sterm := m.Snapshot.Metadata.Index, m.Snapshot.Metadata.Term
if r.restore(m.Snapshot) {
r.logger.Infof("%x [commit: %d] restored snapshot [index: %d, term: %d]",
r.id, r.raftLog.committed, sindex, sterm)
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: r.raftLog.lastIndex()})
} else {
//snapshot消息比较旧
r.logger.Infof("%x [commit: %d] ignored snapshot [index: %d, term: %d]",
r.id, r.raftLog.committed, sindex, sterm)
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: r.raftLog.committed})
}
}
// restore recovers the state machine from a snapshot. It restores the log and the
// configuration of state machine.
func (r *raft) restore(s pb.Snapshot) bool {
//snapshot的index比自身committed要小,说明已有这些数据,返回false
if s.Metadata.Index <= r.raftLog.committed {
return false
}
// 自身日志条目中有相应的term和index,说明已有这些数据,返回false
if r.raftLog.matchTerm(s.Metadata.Index, s.Metadata.Term) {
r.logger.Infof("%x [commit: %d, lastindex: %d, lastterm: %d] fast-forwarded commit to snapshot [index: %d, term: %d]",
r.id, r.raftLog.committed, r.raftLog.lastIndex(), r.raftLog.lastTerm(), s.Metadata.Index, s.Metadata.Term)
r.raftLog.commitTo(s.Metadata.Index)
return false
}
//...
//restore log
r.raftLog.restore(s)
//restore configuration of state machine.
r.prs = make(map[uint64]*Progress)
r.learnerPrs = make(map[uint64]*Progress)
//分别重储普通节点和learner的信息
r.restoreNode(s.Metadata.ConfState.Nodes, false)
r.restoreNode(s.Metadata.ConfState.Learners, true)
return true
}
//重储节点信息,主要是更新progress的match和next值
func (r *raft) restoreNode(nodes []uint64, isLearner bool) {
for _, n := range nodes {
match, next := uint64(0), r.raftLog.lastIndex()+1
if n == r.id {
match = next - 1
r.isLearner = isLearner
}
r.setProgress(n, match, next, isLearner)
r.logger.Infof("%x restored progress of %x [%s]", r.id, n, r.getProgress(n))
}
}
- state machine或者业务层接收到要处理snapshot的信息。将数据保存到本地snapshot文件中,以及MemoryStorage中,并通过publishSnapshot发送nil消息给处理消息的部分。及上一部分中的readCommits。这样就可以从snapshot中加载出当时的state machine的状态。
- 节点只需从leader那里正常同步snapshotIndex之后的数据即可。
//func serveChannels
if !raft.IsEmptySnap(rd.Snapshot) {
rc.saveSnap(rd.Snapshot)
rc.raftStorage.ApplySnapshot(rd.Snapshot)
rc.publishSnapshot(rd.Snapshot)
}
func (rc *raftNode) publishSnapshot(snapshotToSave raftpb.Snapshot) {
if raft.IsEmptySnap(snapshotToSave) {
return
}
log.Printf("publishing snapshot at index %d", rc.snapshotIndex)
defer log.Printf("finished publishing snapshot at index %d", rc.snapshotIndex)
if snapshotToSave.Metadata.Index <= rc.appliedIndex {
log.Fatalf("snapshot index [%d] should > progress.appliedIndex [%d] + 1", snapshotToSave.Metadata.Index, rc.appliedIndex)
}
rc.commitC <- nil // trigger kvstore to load snapshot
rc.confState = snapshotToSave.Metadata.ConfState
rc.snapshotIndex = snapshotToSave.Metadata.Index
rc.appliedIndex = snapshotToSave.Metadata.Index
}